Supercomputing without Supercomputers


Enabling new frontiers in science and technology by designing new algorithmic foundations
Supported by:


What we do
Expanding the boundaries of computation
Cambridge Brain is a deep technology company that designs foundational algorithms (such as optimization and learning) with the aim of improving performance by one or more orders of magnitude. The objective of our technology is two-fold:
Efficiency that enables assessable supercomputing: by significantly reducing the number of computations required for critical applications (in optimization and learning), and enabling supercomputing on modest hardware.
Scaling to solve more difficult problems: to enable new frontiers in science and technology which are held back due to computational cost or complexity of solving larger scale problems.
We use the Technology Readiness Level (TRL) system to to estimate maturity of technologies, which is a metric developed by NASA. Our combinatorial optimization framework is at TRL 5 (validated for applications in logistics and DNA assembly in peer-reviewed work). We have conducted various feasibility to assess the right target areas for our approach.


How we create value for our users
Solving the previously unsolvable
Current capability: Our combinatorial optimization tools have been validated in various applications through a PhD thesis. It will enable solving previously unsolvable challenges and improve the quality of existing solutions. These validated applications span scheduling, logistics, and DNA assembly software. We welcome collaboration on validating additional applications.
The benefit of our methods are most observable when one or more of the following requirements exist:
Large-scale combinatorial optimization that were previously unsolvable due to their size
High quality optimization, even without requiring big data
Lowering the computational cost for optimization


R&D: Our general learning technology is in its infancy and operates under a new mathematical framework (it is similar to Learning Using Statistical Invariants (LUSI)). This approach is far from being a competitor to the state of the art of machine learning, however, if it succeeds, it could theoretically reach far higher rates of learning per unit of data. The development of such a disruptive technology requires significant further innovation, and we believe that our background uniquely positions us to take on this challenge.
How we do it
An alternative paradigm
While the prevailing computing and AI paradigm assumes that achieving more powerful models requires increased data, energy, and environmental impact, the human brain comprehends the world with an energy consumption 12 Watts, comparable to a light bulb, and despite significant data limitations. This suggests that there must be better ways to design efficient computational systems.
Our methods are influenced by our multidisciplinary studies in complexity theory (computer science), dimension reduction techniques (abstract mathematics), efficient representation (information theory), and observations about the computational efficiency of the brain and other biological systems (cognitive neuroscience). By synthesizing ideas of different fields, we have developed theoretical frameworks that enables computational systems which significantly narrow the search space for accurate solutions and accelerates convergence rates. This methodology is conceptually similar to a machine learning paradigm called Learning Using Statistical Invariants (LUSI).
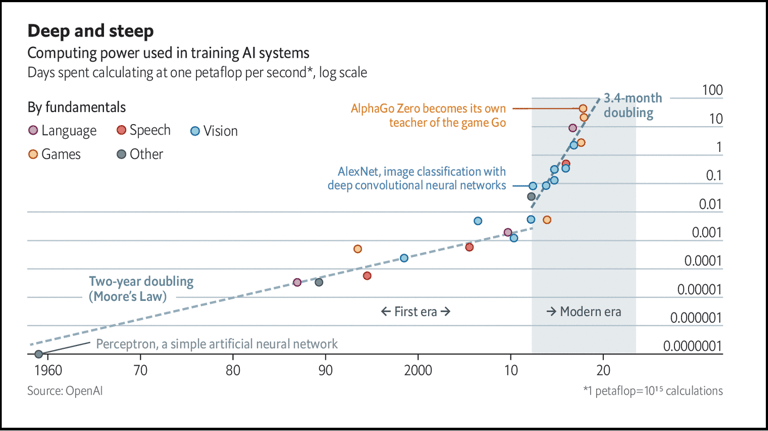
The need for enormous resources for training models and solving complex problems is often the limiting factor in computing. Billions of dollars are invested in advanced technologies like quantum computing to meet the growing need for more computational power. More strikingly, trillions of dollars is expected to be spent on increasing the computational resources such as GPUs and data centers in the coming decade.